Évaluer la performance d’un test de diagnostic repose sur deux critères clés : la sensibilité (capacité à identifier les vrais positifs) et la spécificité (capacité à identifier les vrais négatifs). Pour garantir la validité clinique de ce dispositif, la taille de l’échantillon doit être déterminée via une approche de puissance conjointe (conjoint power).
Contrairement aux méthodes classiques, cette approche assure que l’étude a une probabilité élevée d’atteindre simultanément ses objectifs de sensibilité et de spécificité, tout en contrôlant le risque global d’erreur de Type I (α). Elle prend aussi en compte la corrélation naturelle entre ces deux critères, souvent observée dans la pratique. La puissance conjointe s’impose aujourd’hui comme la norme de référence pour les études de performance destinées à la FDA.
Pourquoi la puissance conjointe est essentielle dans un test de diagnostic
Limites de l’approche classique
L’approche la plus courante pour estimer la taille d’échantillon dans une étude de performance diagnostique consiste à calculer séparément le nombre de sujets nécessaires pour la sensibilité (Se) et pour la spécificité (Sp), puis à retenir la valeur la plus grande, c’est à dire : nfinal = max (nSe , nSp).
Cette méthode, bien que simple à appliquer, reste approximative et présente deux limites :
- Risque d’erreur accru (α) : en testant séparément la sensibilité et la spécificité, on multiplie les tests statistiques. Ceci augmente le risque de conclure à tort qu’un critère est atteint (erreur de type I).
- Puissance non garantie : elle ne garantit pas que les deux critères atteignent simultanément la puissance statistique souhaitée.
En pratique, chaque critère peut viser une puissance élevée, par exemple 90 %. Pourtant, la probabilité d’obtenir les deux performances en même temps est plus faible. Si la puissance est de 90 % pour la sensibilité et 90 % pour la spécificité, la puissance conjointe chute. En supposant leur indépendance, elle n’est que de 0,9 × 0,9 = 0,81, soit 81 % seulement.
Cette perte de puissance d’environ 9 % n’est pas négligeable.
En effet, elle montre que la méthode classique peut sous-estimer la taille d’échantillon.
Par conséquent, une taille trop faible rend l’étude incapable de démontrer pleinement la performance du test.
Ainsi, les deux composantes — sensibilité et spécificité — risquent de ne pas être validées ensemble.
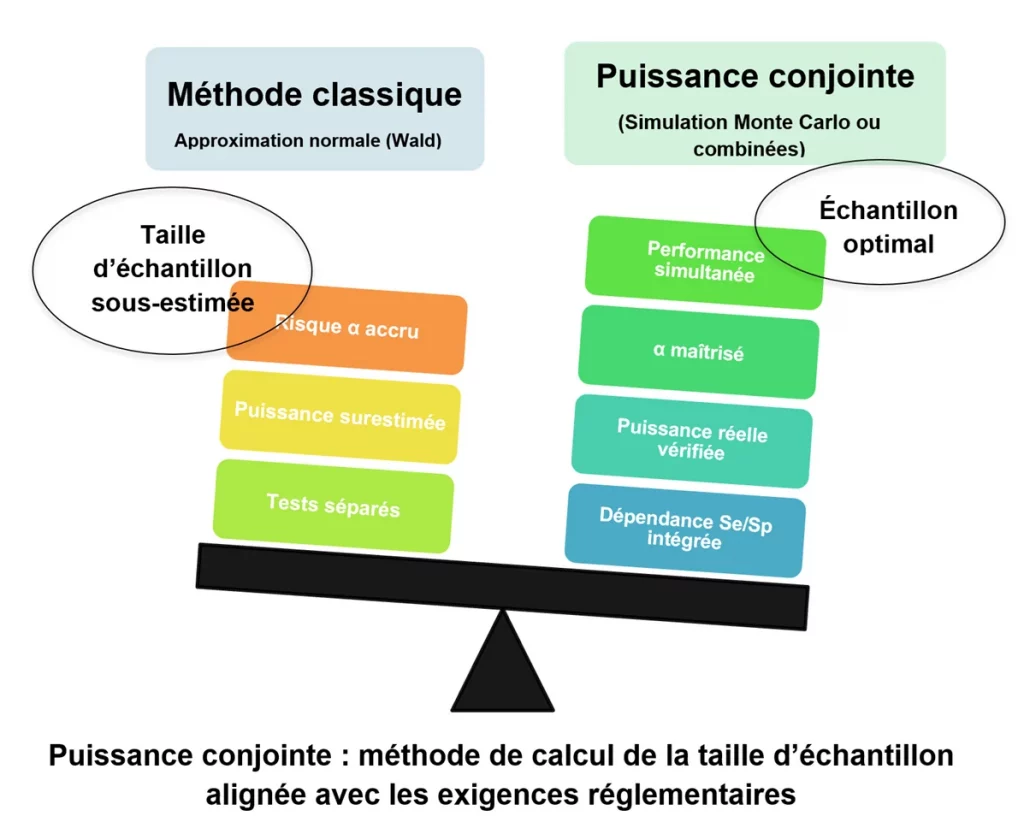
Puissance conjointe : taille d’échantillon plus juste
L’approche par puissance conjointe (ou conjoint power) permet de surmonter les limites de la méthode classique en faisant de la performance simultanée l’objectif central de l’étude.
Elle repose sur trois principes essentiels :
- Un contrôle rigoureux de l’erreur α : dès la conception, l’approche ajuste le risque d’erreur global entre les deux critères (sensibilité et spécificité), par exemple à l’aide de méthodes reconnues comme celles de Bonferroni ou de Holm. Cela garantit que le risque de fausse conclusion reste maîtrisé.
- Une garantie de succès simultané : la puissance cible (par exemple 90 %) correspond ici à la probabilité que la sensibilité et la spécificité soient toutes deux conformes aux seuils attendus. Autrement dit, l’étude vise à démontrer les deux performances à la fois, et non l’une ou l’autre.
- La prise en compte de la dépendance entre Se et Sp : contrairement à l’approche séparée, cette méthode reconnaît que sensibilité et spécificité peuvent être corrélées. Intégrer cette dépendance rend le calcul de taille d’échantillon plus juste et plus efficace.
En résumé, viser la puissance conjointe pour l’évaluation des tests de diagnostic n’est pas seulement une précaution méthodologique : c’est une exigence pour garantir que l’étude démontre de manière robuste la performance globale du dispositif de diagnostic sur les deux dimensions clés de validité.
Calcul de la Taille d’Échantillon avec la Puissance Conjointe : L’Impératif de la Simulation
Le calcul de la taille d’échantillon pour une puissance conjointe ne repose pas sur une formule unique que l’on pourrait simplement appliquer. Il s’agit plutôt d’un processus itératif, fondé sur des tests d’hypothèse répétés et des simulations statistiques, dont le but est d’estimer la probabilité réelle d’atteindre simultanément les objectifs de sensibilité et de spécificité.
L’outil le plus adapté pour cette démarche est la simulation de Monte Carlo, une méthode numérique puissante qui permet de reproduire un grand nombre d’expériences virtuelles pour estimer la performance d’un plan d’étude.
Pourquoi la simulation est-elle indispensable ?
Les tests de performance diagnostique ne respectent pas toujours les conditions idéales supposées par les formules classiques. Deux raisons principales expliquent pourquoi les méthodes analytiques simples ne suffisent pas dans ce contexte :
1. La nature binomiale des données
Les résultats d’un test diagnostique (vrais positifs, faux négatifs, vrais négatifs, etc.) suivent une distribution binomiale, et non une loi normale. Autrement dit, les observations ne prennent que deux valeurs possibles – “vrai / faux”, “positif / négatif” -, ce sont donc des variables binaires, et non continues comme un poids ou une tension artérielle.
Les formules classiques, comme celles basées sur l’approximation normale (méthode de Wald), reposent sur des hypothèses qui ne sont pas tout à fait vraies ici.
Les calculs exacts nécessitent alors des fonctions plus complexes (comme la distribution bêta ou les tests de score inversés), ce qui rend nécessaire une approche numérique.
2. La corrélation entre sensibilité et spécificité
Dans la pratique, la sensibilité et la spécificité ne sont pas indépendantes.
Par exemple, lorsqu’on modifie le seuil d’un test, on peut améliorer la sensibilité, mais souvent au détriment de la spécificité. Cette dépendance rend difficile un calcul exact à la main.
L’apport de la simulation
La simulation permet de modéliser cette dépendance entre les deux paramètres et d’estimer de manière réaliste la puissance conjointe.
Concrètement, il s’agit de tester virtuellement des centaines de scénarios avec différentes tailles d’échantillon, jusqu’à trouver celle qui permet d’atteindre la puissance conjointe souhaitée (par exemple 90 %).
Cette approche, aujourd’hui indispensable, est mise en œuvre à l’aide de logiciels statistiques performants (tels que R, SAS ou PASS), qui garantissent la précision et la robustesse des résultats.
En partique comment fonctionne la Simulation de Monte Carlo ?
Quand on veut calculer la taille d’échantillon pour garantir une puissance conjointe, il n’existe pas de formule “toute faite”.
Les relations entre sensibilité et spécificité sont souvent complexes et dépendent de nombreux paramètres (seuils, effectifs, variabilité, corrélation entre les deux). C’est pourquoi les statisticiens utilisent une méthode numérique appelée simulation de Monte Carlo.
Le principe de la simulation
Le principe est simple : le logiciel statistique reproduit virtuellement l’étude des centaines ou des milliers de fois.
Chaque essai simulé correspond à une étude complète, dans laquelle on tire aléatoirement des résultats (vrais positifs, faux négatifs, vrais négatifs, etc.) selon leur probabilité théorique, en respectant la distribution binomiale des données. Autrement dit, on recrée artificiellement ce qui se passerait si l’étude était réellement réalisée en laboratoire.
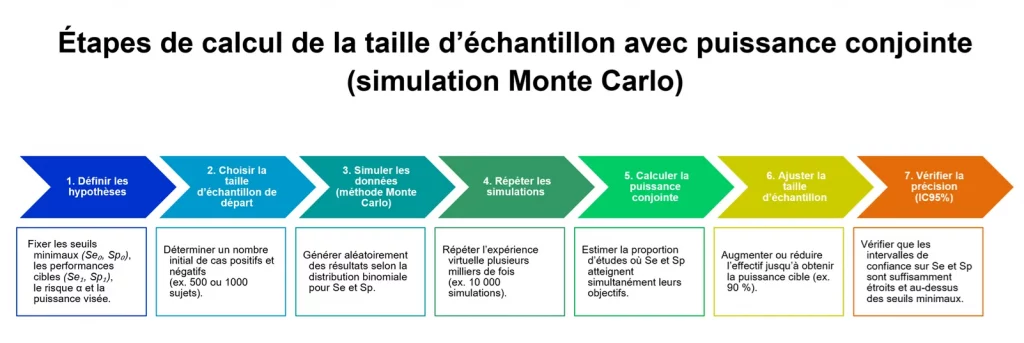
Les étapes de la simulation par la méthode Monte Carlo
- Définir les hypothèses unilatéraux et les paramètres clés
- Les performances cibles (par exemple, Se₁ = 0,90 et Sp₁ = 0,90),
- On fixe d’abord les valeurs seuils ou valeurs minimales acceptables (Se₀ et Sp₀)
- le risque d’erreur α et la puissance conjointe recherchée (souvent 90 %).
- Choisir une taille d’échantillon de départ
Le logiciel démarre avec un nombre de cas positifs et négatifs (par exemple 500 ou 1000) et simule les résultats possibles selon ces valeurs. - Simuler l’étude plusieurs milliers de fois
Le programme répète cette expérience virtuelle (souvent 10 000 fois).
Pour chaque itération, il vérifie si les deux objectifs — atteindre Se₁ et Sp₁ — sont atteints simultanément. - Calculer la puissance conjointe obtenue
On calcule la proportion d’études simulées où les deux critères sont validés.
Si cette proportion est inférieure à la puissance visée (par exemple < 90 %), la taille d’échantillon est augmentée et la simulation est relancée.
Ce processus se poursuit jusqu’à trouver la taille d’échantillon minimale qui permet d’obtenir la puissance conjointe souhaitée.
En pratique, cette méthode est implémentée dans des logiciels comme R, SAS, ou nQuery. Leurs programmes automatisent les simulations et affichent la puissance conjointe obtenue pour chaque taille d’échantillon testée.
Vérifier la précision : le rôle des intervalles de confiance (IC95%)
Une fois la taille d’échantillon obtenue, il faut vérifier qu’elle garantit une estimation précise des performances.
C’est le rôle des intervalles de confiance (IC95%). Cette étape complète le raisonnement statistique. Elle ne vise plus à démontrer la performance, mais à s’assurer que les résultats seront stables dans une étude réelle.
Pourquoi les IC95% sont indispensables ?
Même avec une puissance de 90 %, une estimation peut rester trop incertaine. Un IC95% trop large signifie que les résultats manquent de précision. Plus l’échantillon est grand, plus l’intervalle est étroit, donc plus la mesure est fiable.
Le principe de la vérification
Pour chaque paramètre (Se et Sp), on calcule un IC95%, par la méthode exacte de Clopper-Pearson (adaptée aux données binomiales). Un intervalle de confiance à 95 % signifie que, si l’étude était répétée un grand nombre de fois, 95% des intervalles obtenus contiendraient la vraie valeur de la performance du test.
Par exempel :
- Si Se = 0,90 et IC95% = [0,85 – 0,94], on estime avec 95 % de confiance que la vraie sensibilité se situe entre 85 % et 94 %.
- Si l’intervalle est trop large (par exemple ±10 %), la taille d’échantillon doit être augmentée pour améliorer la précision.
Les logiciels statistiques calculent automatiquement ces IC à partir des données simulées, pour vérifier que :
- les bornes inférieures des IC95% de Se et Sp dépassent les seuils fixés (Se₀ et Sp₀),
- et que les intervalles sont suffisamment étroits pour garantir la robustesse des résultats.
Conclusion
Le calcul de la taille d’échantillon dans une étude de performance diagnostique repose sur une approche rigoureuse et moderne.
La puissance conjointe garantit une évaluation simultanée de la sensibilité et de la spécificité.
La simulation de Monte Carlo permet d’estimer cette probabilité de réussite dans des conditions proches du réel.
Enfin, la vérification par les intervalles de confiance renforce la crédibilité des résultats obtenus.
Ces étapes assurent une étude statistiquement solide, scientifiquement valide et conforme aux attentes des autorités réglementaires.
Elles traduisent une approche centrée sur la qualité de la démonstration clinique, bien au-delà d’un simple calcul numérique.