Lors d’une étude où l’on souhaite comparer des variables quantitatives entre plusieurs groupes, on pense rapidement à utiliser un test t de Student ou une ANOVA. Ces tests sont en effet puissants et souvent privilégiés en première intention. Cependant, ce sont des tests paramétriques, qui reposent sur certaines hypothèses, dont l’une des plus importantes est la normalité des données. Autrement dit, pour pouvoir les appliquer dans de bonnes conditions, on suppose que la distribution des données est approximativement normale.
Mais que signifie réellement la normalité des données ?
Pourquoi est-elle importante ?
Et comment peut-on la vérifier en pratique ?
Dans cet article, nous proposons une explication simple et accessible, destinée aux non-statisticiens, pour comprendre pourquoi et comment évaluer la normalité des données quantitatives.
Nous verrons également comment réaliser un test formel de normalité, et dans quels cas cette étape est réellement nécessaire avant d’utiliser un test paramétrique.
Pourquoi mesurer la distribution des données ?
L’une des bases de l’analyse statistique consiste à examiner la distribution des données de la variable étudiée, puis à la comparer à des modèles théoriques de distribution. Parmi les plus couramment utilisés, on retrouve notamment la loi normale, la loi binomiale et la loi de Poisson.
L’objectif n’est pas seulement descriptif : il s’agit de vérifier si les données peuvent raisonnablement être décrites par un modèle théorique donné, afin de pouvoir appliquer toutes les propriétés mathématiques de ce modèle aux données étudiées.
Par exemple, le test t de Student et l’ANOVA sont des tests paramétriques qui reposent sur les propriétés de la loi normale. Lorsque cette hypothèse est raisonnablement respectée, ces tests permettent d’estimer des effets, de calculer des probabilités et de prendre des décisions statistiques de manière efficace.
C’est pour cette raison que l’on s’intéresse à la normalité des données avant d’appliquer ces tests : non pas parce que la normalité doit être parfaite, mais parce qu’elle conditionne la validité et l’interprétation des résultats.
Loi Normale
La loi normale est l’une des distributions théoriques les plus utilisées en statistique. Elle s’applique principalement aux variables quantitatives continues.
En biologie, en médecine et plus généralement en sciences de la vie, la majorité des caractères biologiques observés dans la nature suivent une une loi normale dans les populations génerales naturelles. Par exemple, la taille des individus, les concentrations biologiques (comme le nombre de globules rouges) ou encore des délais biologiques (incubation d’une maladie) présentent une distribution normale.
Les distributions normales permettent de définir des valeurs de référence à partir de grandes populations, généralement décrites par une moyenne (µ) et d’un écart type (σ). En pratique, les mesures individuelles d’un même caractère peuvent alors être comparées à ces valeurs de référence afin d’évaluer si elles se situent dans la variabilité attendue de la population dite « normale ».
C’est précisément le principe utilisé en biologie médicale : les résultats d’analyses biologiques (par exemple une concentration sanguine) sont interprétés en les comparant à des intervalles de référence établis sur de larges populations saines.
Graphiquement, la distribution de ces mesures se représente par une courbe en cloche, symétrique autour de la moyenne (µ), traduisant le fait que la majorité des valeurs se concentre autour de cette valeur centrale, tandis que les valeurs plus éloignées deviennent progressivement plus rares. La dispersion des données autour de la moyenne est quantifiée par l’écart type (σ).
Pour mieux comprendre cette notion, nous utiliserons un exemple concret : les mesures de la taille (en cm) d’individus. Cet exemple servira de fil conducteur pour illustrer la notion de normalité et son comportement lorsque la taille de l’échantillon augmente.

Exemple Taille des individus en cm
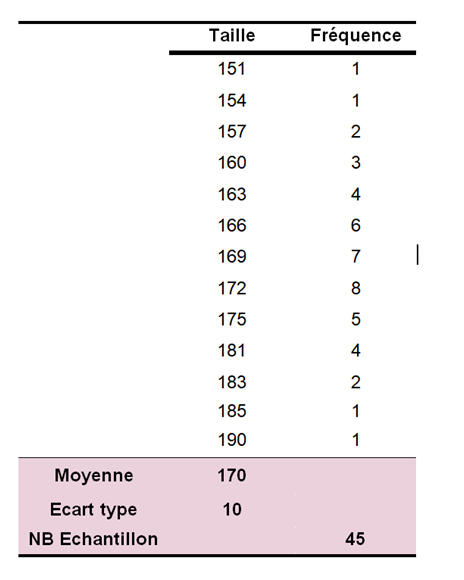
Dans un groupe de 45 sujets pris au hasard, c’est-à-dire dans un échantillon aléatoire, nous mesurons dans un premier temps leur taille en centimètres. Nous calculons ensuite la moyenne et l’écart-type de cet échantillon :
n = 45, moyenne µ = 170 cm, écart-type σ = 10 cm.
Dans un deuxième temps, pour chaque classe de taille (par exemple des classes de 1 cm), nous calculons la fréquence qui veut dire le nombre de sujets appartenant à chaque classe. À partir de ces fréquences, nous traçons l’histogramme de la variable Taille.
Ci-dessous sont présentées les données de l’échantillon ainsi que l’histogramme de fréquence correspondant.
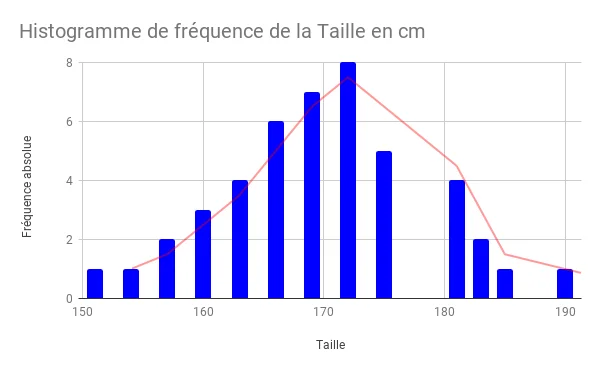
Si nous prenons ensuite un échantillon plus grand de 100 sujets, nous répétons les mêmes étapes : calcul de la moyenne et de l’écart-type, puis nous traçons l’histogramme (et éventuellement du polygone de fréquence ci-dessous).
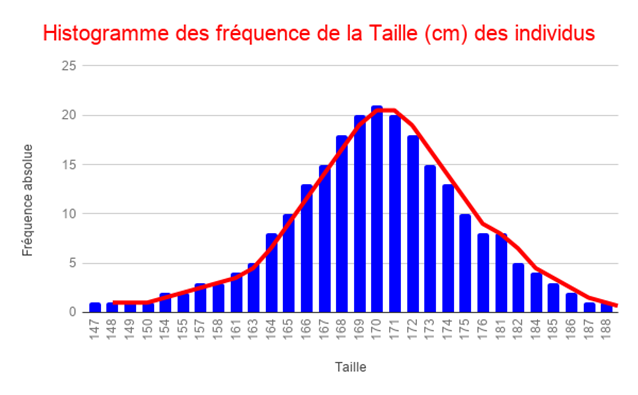
De la même manière, en augmentant progressivement la taille de l’échantillon (1000 individus, 10 000 individus, puis une population très large), nous observons que l’histogramme devient de plus en plus régulier et symétrique. Au fur et à mesure que la taille de l’échantillon augmente et que les classes deviennent plus fines, la forme de l’histogramme se rapproche d’une courbe en cloche.
Cette courbe correspond à la distribution normale caractérisée par une moyenne µ = 170 cm et un écart-type σ = 10 cm. Cela illustre que, dans la population générale, la taille des individus suit une distribution normale.

Caractéristiques de la courbe de la loi Normale
Comme déjà mentionné plus haut, la majorité des caractères en biologie, comme la taille, le poids, la PA, le taux de triglycérides, le QI, la concentration de la vitamine C dans l’orange,…etc. suivent une distribution normale caractérisée par une courbe en cloche symétrique autour d’une moyenne µ et d’un écart type σ.
L’aire sous la courbe représente 100% des individus de la population. La majorité des individus, 68,28% de cette population ont une valeur moyenne ± 1 écart type. Et 95% des individus ont une valeur moyenne ± 2 écart types.
En application à notre exemple la Taille (cm), nous pouvons affirmer que 68,28% des sujets adultes de la population mesurent entre 160 cm et 180 cm (µ =170 ± σ =10 cm). Et les 95% de la population mesurent entre 150 et 190 cm. Seulement les 5 % restants ont des mesures au-delà de ces dernières valeurs.
Caractéristiques de la courbe de la loi Normale
Comme mentionné précédemment, de nombreux caractères en biologie et en médecine, tels que la taille, le poids, la pression artérielle, le taux de triglycérides, le QI ou encore certaines concentrations biologiques, suivent une distribution normale. Cette distribution est caractérisée par une courbe en cloche, symétrique autour d’une valeur centrale appelée moyenne (µ), et par une dispersion mesurée par l’écart-type (σ).
L’aire totale sous la courbe représente 100 % des individus de la population. Dans une distribution normale, environ 68,28 % des individus ont une valeur comprise entre la moyenne ± 1 écart-type, et environ 95 % ont une valeur comprise entre la moyenne ± 2 écarts-types.
En appliquant ces propriétés à notre exemple de la taille (en cm), on peut dire qu’environ 68,28 % des adultes de la population mesurent entre 160 cm et 180 cm (µ = 170 cm ± σ = 10 cm). De même, environ 95 % des individus mesurent entre 150 cm et 190 cm. Les 5 % restants correspondent à des valeurs plus éloignées de la moyenne, situées en dehors de cet intervalle.

Propriétés de la loi Normale
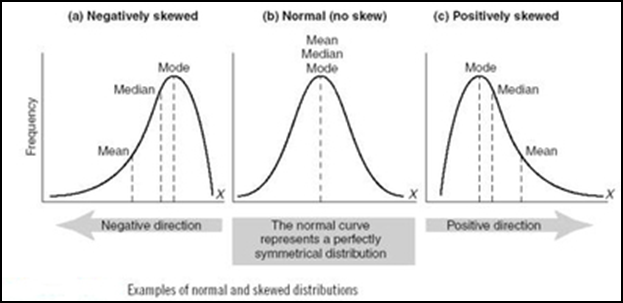
La loi normale, également appelée loi de Gauss (du nom du mathématicien Karl Friedrich Gauss, 1777–1855), est une distribution symétrique centrée autour de la moyenne (µ). Dans une loi normale, les valeures de la moyenne, la médiane et le mode sont égaux.
Une propriété importante de cette distribution est que l’aire comprise entre −1,96 écarts-types et +1,96 écarts-types autour de la moyenne représente environ 95 % de l’aire totale sous la courbe, c’est-à-dire environ 95 % des individus de la population.
L’expression mathématique de la loi normale permet de décrire cette distribution de manière théorique.
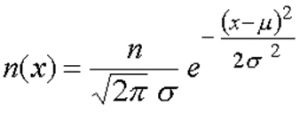
Dans cette expression :
- µ représente la moyenne,
- σ l’écart-type,
- x une valeur prise par la variable ou le caractère étudié (par exemple une taille de 168,7 cm),
- la fonction associée décrit la fréquence ou la densité des individus prenant la valeur x.
Loi Normale centrée réduite
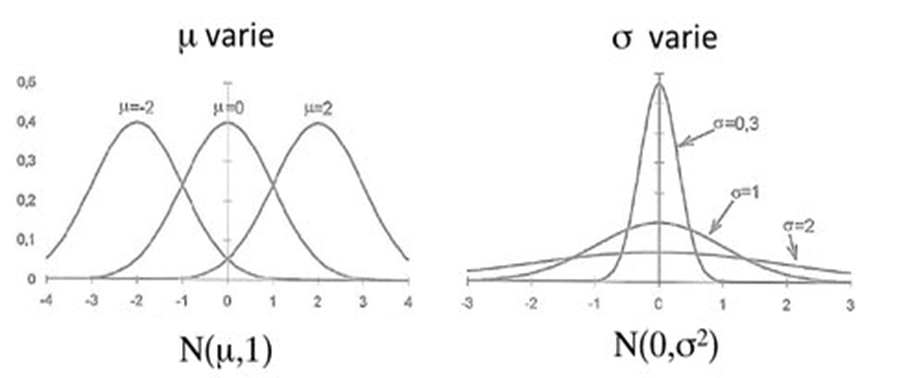
Toutes les variables qui suivent une loi normale peuvent être représentées par une courbe en cloche dont la position et la forme dépendent de leur moyenne (µ) et de leur écart-type (σ).
Afin de pouvoir comparer différentes distributions normales entre elles et d’utiliser une table unique, les statisticiens ont introduit une transformation mathématique permettant de centrer et de réduire les données.
Cette transformation consiste à ramener toute distribution normale à une distribution ayant une moyenne égale à 0 et un écart-type égal à 1.
La distribution obtenue est appelée loi Normale centrée réduite. Elle est caractérisée par :
- une moyenne µ = 0,
- un écart-type σ = 1.
C’est cette distribution standardisée qui est utilisée pour établir les tables de la loi normale, appelées tables de Z, permettant de calculer des probabilités associées aux valeurs observées.

Notion de densité de probabilité
Dans ce contexte, la courbe de la loi normale centrée réduite ne représente plus un nombre d’individus, mais une densité de probabilité. Cela signifie que l’aire sous la courbe, comprise entre deux valeurs de Z, correspond à la proportion (ou probabilité) d’observations situées dans cet intervalle.
Par convention, l’aire totale sous la courbe est égale à 1, soit 100 % de la population. Les tables de la loi normale centrée réduite indiquent alors les aires cumulées sous la courbe, et donc les probabilités associées aux valeurs de Z.
Propriétés de la loi Normale centrée réduite Z
La loi Z est centrée autour de la valeur moyenne = 0 et d’écart type = 1.
95% des valeurs de Z sont comprises entre -1,96 et + 1,96 (ou -2 et +2).
2,5% des valeurs sont < à -1,96 et 2,5% des valeurs sont > à +1,96.
Ces seuils sont largement utilisés en statistique pour la prise de décision, notamment dans les tests d’hypothèses.
Plusieurs lois de probabilités sont dérivées de la loi normale. Les plus utilisées en statistiques et qui serviront pour les tests sont:
- Loi du Chi2
- Loi de Student
- Loi de Fisher
Ces notions sont fondamentales pour comprendre le raisonnement en biostatistique, notamment l’estimation des paramètre d’une population à partir d’un échantillon et l’application et l’interprétation des tests statistiques.
Comment mesurer la Normalité des données ?
Il existe plusieurs moyens pour estimer et visualiser la normalité des données quantitatives.
Par l’examen des paramètres descriptifs
Une première approche consiste à comparer les paramètres descriptifs calculés dans l’échantillon.
- Par exemple, si la moyenne ≈ la médiane ≈ le mode, on peut considérer que la distribution des données est proche d’une loi normale.
- De même, si l’intervalle compris entre −1 et +1 écart-type contient environ 68 % des valeurs (soit 2/3), cela confirme également la normalité.
Par l’observation graphique
Une autre approche consiste à examiner la représentation graphique des données.
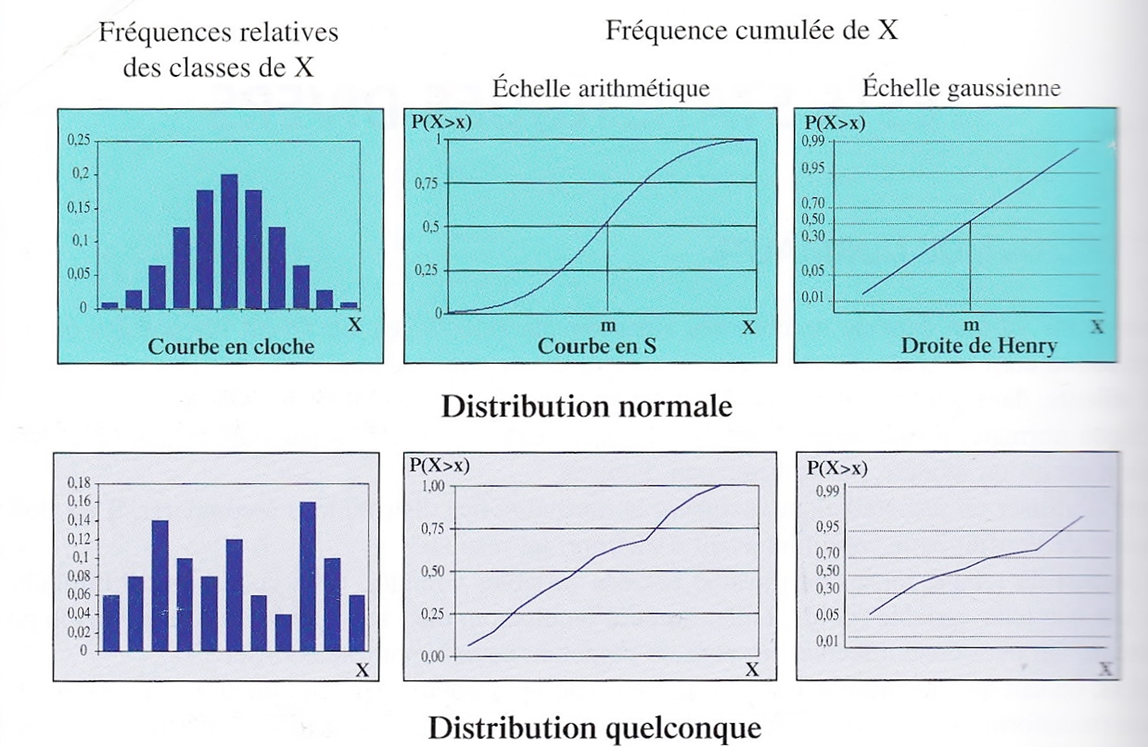
- L’histogramme des fréquences permet de visualiser la distribution.
- Si l’histogramme est symétrique autour de la moyenne et présente une forme en cloche, on peut considérer que les données suivent approximativement une loi normale.
- Les diagrammes en boîte (boxplots) ou les diagrammes de probabilité normale (Q-Q plots) peuvent également aider à détecter des déviations par rapport à la normalité, comme des valeurs extrêmes ou des asymétries.
Test de Normalité
La troisième méthode pour évaluer la normalité des données repose sur l’utilisation de tests statistiques formels, comme le test de Shapiro–Wilk ou le test de Kolmogorov–Smirnov.
Ces tests sont réalisés à l’aide d’un logiciel de statistique et permettent d’évaluer objectivement l’adéquation des données à une distribution normale.
Test de normalité de Shapiro–Wilk
Le test de Shapiro–Wilk est l’un des tests les plus utilisés pour évaluer la normalité d’un échantillon. Il est particulièrement adapté aux petits et moyens échantillons, mais peut également être appliqué à des tailles plus importantes.
Ce test fournit directement une p-value, utilisée pour prendre la décision statistique.
Les hypothèses du test sont définies comme suit :
- Hypothèse nulle (H₀) : la variable dont est issu l’échantillon suit une loi normale.
- Hypothèse alternative (H₁) : la variable dont est issu l’échantillon ne suit pas une loi normale.
Après réalisation du test de Shapiro–Wilk, deux situations sont possibles :
- Si la p-value > 0,05 (au seuil de signification α = 5 %), on ne rejette pas l’hypothèse nulle H₀.
On considère alors que les données sont compatibles avec une distribution normale. - Si la p-value ≤ 0,05, l’hypothèse nulle est rejetée et les données ne suivent pas une distribution normale.
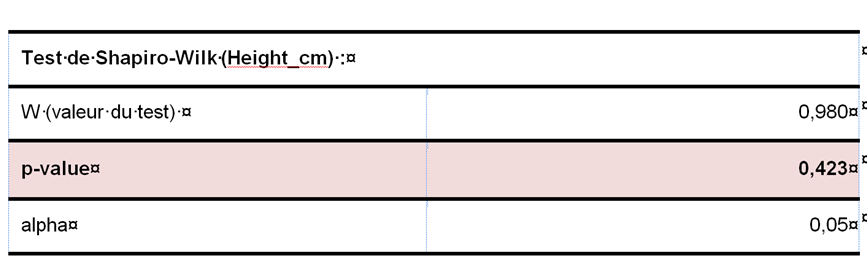
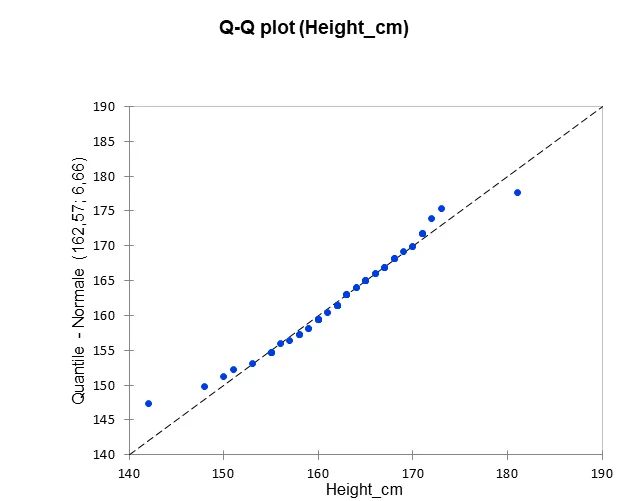
Le tableau ci-dessous présente les résultats d’un test de Shapiro–Wilk.
La statistique du test est W et la p-value obtenue est égale à 0,423.
Cette valeur étant supérieure à 0,05, l’hypothèse nulle est retenue.
On conclut donc que la distribution de la variable Height est compatible avec une loi normale.
Le graphique Q–Q plot confirme cette conclusion en montrant un bon alignement des points autour de la droite théorique.
Par contre le test de Shapiro-Wilk appliqué à la variable Cytorachie (c/ul), donne une p-value <0,0001. Les données de cette variable ne suivent pas une distribution normale.

Test de Normalité de Kolmogorov-Smirnov
Le test de normalité de Kolmogorov–Smirnov est un test formel permettant d’évaluer l’adéquation des données à une loi normale.
Il est généralement utilisé pour des échantillons de grande taille (n ≥ 50), alors que le test de Shapiro–Wilk est souvent privilégié pour les petits et moyens échantillons.
Comme pour tout test de normalité, il compare la distribution observée des données à la distribution théorique normale et fournit une p-value permettant de statuer sur l’hypothèse de normalité.

Conclusion
La loi normale est un modèle théorique décrivant la distribution d’un caractère dans une population générale « idéale ».
En pratique, les populations parfaitement homogènes n’existent pas et les données analysées proviennent le plus souvent d’échantillons sélectionnés, parfois de taille limitée.
Ainsi, un rejet de l’hypothèse de normalité ne remet pas en cause l’intérêt des données, mais doit conduire à adapter la stratégie d’analyse statistique. Dans ces conditions, la distribution observée peut s’écarter plus ou moins de la normalité théorique sans invalider systématiquement l’utilisation des méthodes paramétriques.
L’objectif n’est donc pas d’obtenir une normalité parfaite, mais d’évaluer si l’hypothèse de normalité est raisonnable, au regard du contexte de l’étude, de la taille de l’échantillon et des méthodes statistiques envisagées.
Enfin, il est important de rappeler que les tests de normalité sont sensibles à la taille de l’échantillon. Pour de grands effectifs, de faibles écarts à la normalité peuvent conduire au rejet de l’hypothèse de normalité, sans que cela ait un impact pratique sur l’analyse statistique. Dans ce contexte, il est possible de fixer un seuil de significativité plus strict (par exemple α = 1 %), afin de limiter le risque de conclure à tort à une non-normalité des données. L’objectif reste d’évaluer si l’hypothèse de normalité est raisonnable au regard de la question posée et des méthodes statistiques utilisées.