La p-value accompagne toujours les tableaux des résultats statistiques. Il s’agit d’une valeur calculée lors d’un test statistique, qui permet de déterminer si le résultat observé est statistiquement significatif. Sa valeur aide ainsi à interpréter les résultats et à tirer des conclusions fiables dans le cadre d’une étude.
Pour bien comprendre les résultats d’une analyse statistique, il est donc essentiel de saisir la signification exacte de la p-value.
Dans cet article, nous expliquons comment calculer et interpréter correctement la p-value, le rôle du risque alpha, la différence entre significativité statistique et pertinence scientifique, et pourquoi ce concept fait aujourd’hui l’objet de débats majeurs dans la littérature scientifique.
Que signifie la p-value ?

Lors d’une analyse, le test statistique fournit une valeur, la p-value qui aide à interpréter les résultats d’une étude. Il est donc essentielle de l’inserer dans les tableaux descriptifs des résultats.
Elle indique si la différence ou la relation observée entre les paramètres de l’échantillon atteint un niveau de significativité statistique suffisant pour conclure sur la population étudiée, car les statistiques descriptives proviennent des données de l’échantillon.
Pour conclure sur la significativité des résultats, on compare ensuite la p-value à une valeur seuil appelée risque d’erreur alpha (α).
Afin de mieux comprendre ces notions, nous abordons d’abord certaines bases importantes en statistique, comme l’inférence statistique et les risques d’erreur.
Inférence statistique et rôle de la p-value
L’objectif d’une étude en recherche clinique est de poser une hypothèse scientifique, puis de la vérifier à partir des données recueillies. Cette hypothèse concerne une population donnée, c’est-à-dire l’ensemble des patients ciblés par l’étude.
Population vs échantillon
Il est rarement possible de recueillir les données de tous les individus de cette population, qui peut compter plusieurs milliers de patients. On se base donc sur un échantillon représentatif, c’est-à-dire un sous-groupe choisi de manière à refléter fidèlement les caractéristiques de la population.
L’analyse statistique de cet échantillon permet ensuite d’extrapoler les résultats à l’ensemble de la population, tout en tenant compte de l’incertitude liée à la taille limitée de l’échantillon.
Inférence statistique
L’ensemble des méthodes permettant de tirer ces conclusions s’appelle l’inférence statistique.
Dans ce cadre, la p-value calculée lors du test statistique indique si les résultats observés dans l’échantillon peuvent refléter une différence réelle dans la population.
Exemple concret
Imaginons une étude visant à évaluer un nouveau traitement pour réduire l’Indice de Masse Corporelle (IMC, en kg/m²). L’étude répartit les patients en deux groupes :
- Le premier reçoit le nouveau traitement.
- Le second reçoit un traitement de référence.
La première étape consiste à calculer la moyenne de l’IMC dans chaque groupe.
Si la moyenne du groupe traité est inférieure à celle du groupe témoin, on doit vérifier si cette différence observée dans l’échantillon reflète réellement une différence dans la population.
Pour le savoir, on applique un test statistique formel, par exemple le test t de Student.
Interprétation de la p-value
La p-value obtenue est comparée à une valeur seuil, le risque d’erreur α, fixé à l’avance :
- p-value ≤ α → la différence observée est statistiquement significative dans la population.
- p-value > α → la différence n’est pas significative et peut être due au hasard.
Ainsi, si notre p-value est inférieure à α, nous pouvons conclure que le nouveau traitement est probablement plus efficace que le traitement de référence pour la population étudiée.
Risque d’erreur alpha (α)
Conclure sur l’ensemble de la population à partir des résultats d’un échantillon comporte toujours un risque d’erreur. Plusieurs facteurs peuvent expliquer ce risque: le hasard, les fluctuations d’échantillonnage ou les biais, notamment le biais de sélection.
Biais de sélection
Si les participants de l’échantillon n’ont pas les mêmes caractéristiques que la population cible, l’échantillon n’est pas représentatif.
- Les caractéristiques mesurées peuvent être mal estimées.
- On peut conclure à tort à une différence ou une relation qui n’existe pas réellement dans la population.
Définition du risque alpha
On appelle ce risque de se tromper, le risque de première espèce ou risque d’erreur α.
Il correspond à la probabilité de conclure à une différence entre deux groupes alors que cette différence n’existe pas réellement dans la population. C’est ce qu’on appelle aussi un faux positif.
Limitation et seuil
Pour toute analyse statistique, nous devons accepter ce risque, le minimiser et fixer son seuil avant le début de l’étude.
Dans la pratique, on choisit souvent 5 %, ce qui correspond à un intervalle de confiance de 95 %. Mais selon les études, ce seuil peut diminuer à 1 %.
Lien avec la p-value
Cela dit, pour pouvoir conclure avec certitude à l’existence d’une différence entre deux populations, le résultat du test en l’occurrence la p-value doit être inférieur à la valeur seuil du risque alpha. Donc à la valeur de 0.05 si nous avons fixé le risque α à 5%.
Si α = 0,05 et que p-value = 0,03, la différence observée entre les deux groupes est statistiquement significative.
Test statistique et p-value
En pratique, un test statistique calcule une expression mathématique à partir des données de l’échantillon puis compare cette valeur à une distribution théorique connue.
Selon les données analysées, on utilise différentes lois statistiques :
- loi normale
- loi de Student (t)
- loi de Fisher (F)
- loi du Chi²

Autrefois, cette comparaison se faisait à l’aide de tables statistiques théoriques (table de Student, table Z, table de Fisher ou table du χ²). Aujourd’hui, les logiciels de statistique réalisent automatiquement ces calculs.
Lorsque nous effectuons un test statistique, avec un logiciel ou par calcul, nous obtenons généralement deux résultats :
- la valeur du test statistique (par exemple F, t, Z ou χ²)
- la p-value associée à ce test
Pour simplifier la lecture des résultats, les tableaux statistiques présentent généralement la p-value, car elle permet une interprétation immédiate.
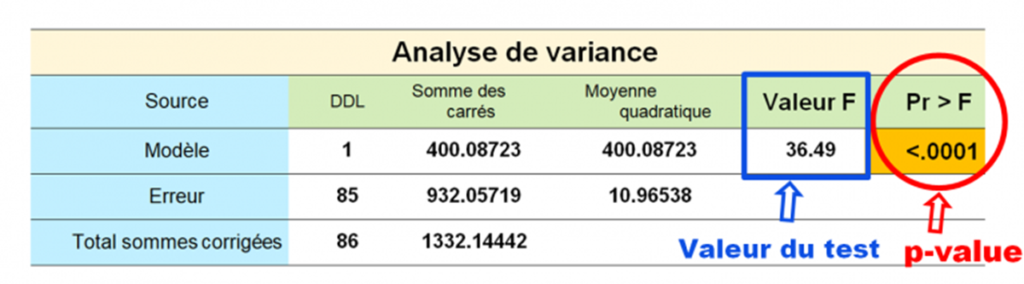
p-value et degré de significativité de l’analyse
Ainsi, en comparant la valeur p calculée à la valeur seuil α, nous obtenons déjà le résultat de l’analyse statistique : soit le résultat est statistiquement significatif, soit il ne l’est pas. Cette comparaison suffit souvent pour conclure.
Mais en réalité, la p-value apporte une information supplémentaire : elle indique à quel point le résultat observé paraît difficile à expliquer par le seul hasard.
En pratique, plus la p-value est petite, plus le résultat observé paraît difficile à attribuer au seul hasard.
Cette formulation reste volontairement simplifiée pour faciliter la compréhension.
En statistique, la définition exacte est la suivante : la p-value correspond à la probabilité d’observer un résultat au moins aussi extrême que celui obtenu, si l’hypothèse nulle (H₀) est vraie.
Deux situations sont alors possibles :
- Si p-value ≤ α, le résultat est statistiquement significatif : la différence observée est difficilement explicable par le seul hasard.
- Si p-value > α, le résultat n’est pas statistiquement significatif : la différence observée peut être expliquée par les fluctuations d’échantillonnage.
Conclusion
Comme nous l’avons vu, la p-value permet d’évaluer si un résultat observé peut être attribué au hasard ou s’il est suffisamment improbable pour être considéré comme statistiquement significatif.
Cependant, cette petite valeur fait aujourd’hui l’objet de nombreux débats dans la communauté scientifique : peut-on l’utiliser comme seul critère pour accepter ou rejeter une hypothèse ? Un seuil fixé à 5 % est-il toujours adapté à toutes les situations d’analyse ?
En pratique, la p-value reste un outil essentiel, mais elle doit toujours être interprétée en tenant compte du contexte scientifique, de la taille d’échantillon et de la pertinence clinique des résultats.
Pour approfondir ce sujet, il est utile de consulter les publications récentes de Nature et d’autres revues scientifiques internationales.